This is a translation of a Korean blog I wrote in 2017. This may differ slightly from the current MySQL 8.0 version.
http://gywn.net/2017/01/automated-recovery-scenarios-for-lazy-mysql-dba/
Overview
Over using MySQL, replication is you know not easy to away from it. It’s like saying that you have to manage multiple servers with the same data soon… It’s a lot of data recovery. This is especially true if the surer environment is in case of data explosion. In addition, the use of early morning backups during recovery will soon be a batch of changes that have been saved since dawn. This is a lot of time consuming data synchronization. In this environment, Simply talk about how to automate recovery.
Prepare
There is no big issue with “Linux+MySQL+Xtrabackup”.
CentOS 6.8 MySQL 5.7.14 Xtrabackup-2.4.3 Pv
Configured to replicate data based on an existing Binlog Position-based replication rather than GTID. I would take SCP for pull the data without any errors.
This means that you will soon have to pair the replication node with the id_rsa.pub key in advance so that you can pull the data without a password for authentication. That means you need to be prepared to access the server without a password.
server1$ ssh mysql@server2 server2$ ssh mysql@server1
Restore Scenario
Depending on the characteristics of the service or individual preferences. The most important thing is the recovery efficiency. Of course, there should be little service impact before efficiency. If so, I would say. You need to control your data transfer traffic. In general, if you have a recovery case, you can consider two cases.
A case that configures slaves with data from slaves. A case that adds another same slave to the current slave. The Slave Status information of the slave that is being dictated by the data becomes the configuration information for the recovery slave.
- restore from master data
As a case to add slaves to the data of the master. The Binlog position of the server is the information for the slave configuration. -
restore from slave data
A case that configures slaves with data from slaves. A case that adds another same slave to the current slave. The Slave Status information of the slave that is being dictated by the data becomes the configuration information for the recovery slave.
Before proceeding, It is shared the explains about automatic recovery scenario not for the my personal script. I had skip for explains that validation check or password crypt.
This is a data recovery advance knowledge. The bottom of xtrabackup read the manual first and I am sure it will be a great help.
https://www.percona.com/doc/percona-xtrabackup/2.4/howtos/setting_up_replication.html
case 1) restore from master data
As I told you earlier. I received the data from the master, as a case to configure slaves right at the bottom. A case that organizes data in the same way as the bottom image.
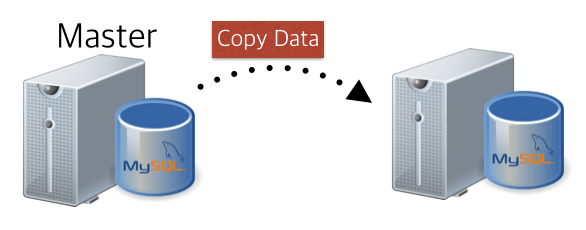
1) Pulling data
During the last course of Xtabackup… The process of copying non-InnoDB data… If you do not give the --no-lock option, you will perform a global Lock during the data copy to ensure the data consistency. In other words, it affects the service.
Fill out the innobackupex part directly into the shell and complete it in one room as shown below. Control the backup data that is sent to the streaming to “pv” (50 MB per second, make even weaker servers)…
ssh -o StrictHostKeyChecking=no mysql@${TARGET_HOST} \
"innobackupex \
--host='127.0.0.1' \
--user='backupuser' \
--password='backuppass' \
--no-lock \
--stream=xbstream \
/data/backup | pv --rate-limit 50000000" 2> innobackupex.log \
| xbstream -x 2> xbstream.log
You can view the two logs of “innobackupex.log” and “xbstream.log”” and validate the backup data that has been shown. The “innobackupex.log” is “completed OK!”, which would normally result in data being displayed.
2) Apply redo log
To proceed with the assumption that the advanced process has been performed normally. The process of applying data that has changed while the data is being backed up and transferred. This is also the end of the innobackupex.log “completed OK!” and you can see that the log has been applied normally.
innobackupex --apply-log . 2>> innobackupex.log
3) configuration of slave
Finally, The process of extracting the position of the master to configure the actual slave. The location information is extracted as follows from the “xtrabackup_binlog_pos_innodb” that is created after the Apply log. Usually, the master’s binary log position is recorded by a tab separated as shown below.
mysql-bin.000001 481
I defined log position with sed command as below.
MASTER_LOG_FILE=`sed -r "s/^(.*)\s+([0-9]+)/\1/g" xtrabackup_binlog_pos_innodb` MASTER_LOG_POS=`sed -r "s/^(.*)\s+([0-9]+)/\2/g" xtrabackup_binlog_pos_innodb`
Now, the master server has also been determined, and the binary log position for the replication configuration is also defined. Let’s configure the slave as shown below.
echo "change master to
master_host='${TARGET_HOST}',
master_user='repl',
master_password='replpass',
master_log_file='${MASTER_LOG_FILE}',
master_log_pos=${MASTER_LOG_POS};
start slave;"\
| mysql -uroot -pxxxxxx
This is done by leveraging the master data as shown below without a large crowd to configure the new slave.
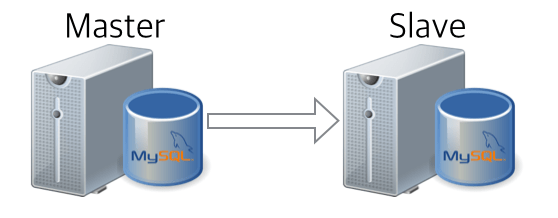
case 2) restore from slave data
Second case… Using data from the current slave server to add new slave servers. It has the following data flow: A scenario where you import data from a normally running slave server and configure additional slaves of the same topology based on the slave information for that slave.
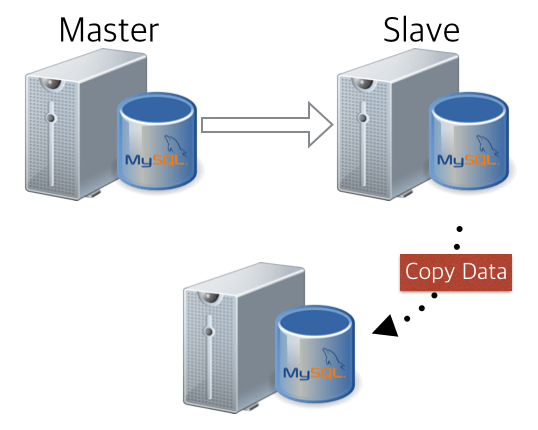
1) pulling data
This time, the process of releasing backup streaming data from the slaves directly into xbstream, as well as throughput control to PV.
Specify the --slave-info option as shown below for the purpose of dictating the slave position differently than the previous case. (To give this option, record the slave state.)
ssh -o StrictHostKeyChecking=no mysql@${TARGET_HOST} \
"innobackupex \
--host='127.0.0.1' \
--user=backupuser \
--password='backuppass' \
--slave-info \
--stream=xbstream \
/data/backup | pv --rate-limit 50000000" 2> innobackupex.log \
| xbstream -x 2> xbstream.log
Similarly, you can view the two logs of innobackupex.log and xbstream.log, and validate the backup data that has been available. In “innobackupex.log”, “Completed OK!” is the end of the data, and the xbstream.log result has been released properly with no content..
2) Apply redo log
While data is being backed up and transferred, it does the same as before to apply the changed data. This is also the end of the “innobackupex.log” “completed OK!” which is normally handled.
innobackupex --apply-log . 2>> innobackupex.log
3) configuration of slave
The slave position is now… I have to define a little differently from what I extracted from the master. You must first identify the binary log position in “xtrabackup_slave_info”.
Finally. The process of extracting the position of the master to configure the actual slave. The location information is extracted as follows from the “xtrabackup_binlog_info” that is created after the Apply log. Usually, the master’s binary log position is recorded by a tab separated as shown below. It is actually stored in the following form.
CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=481
MASTER_LOG_FILE=`sed -r "s/(.*)MASTER_LOG_FILE='(.*)', MASTER_LOG_POS=([0-9]+)/\2/g" xtrabackup_slave_info` MASTER_LOG_POS=`sed -r "s/(.*)MASTER_LOG_FILE='(.*)', MASTER_LOG_POS=([0-9]+)/\3/g" xtrabackup_slave_info`
Getting a binary log position up here is a big move. The problem is, where do I get the information about the server that actually replication? Of course, this can be extracted from a separate monitoring tool. Or you can push the master information somewhere on a regular basis… The way I chose was to get into the target slave equipment that came with the data, look at the Slave Status directly, and retrieve the master server information that I am currently looking at.
MASTER_HOST=`mysql -urepl -preplpass -h ${TARGET_HOST} -e 'show slave status\G' | grep 'Master_Host: ' | sed -r 's/\s*(Master_Host: )//g'|sed -r 's/\s*//g'`
One complaint.. When creating a "xtrabackup_binlog_info" file in xtrabackup, why not record the master information that the slave is looking at.
Now, the master server has also been recognized, and the binary log position for the replication configuration is also defined… Let's configure the slave as shown below. The master host (found earlier) has changed the actual master's host, not the target host.
echo "change master to
master_host='${MASTER_HOST}',
master_user='repl',
master_password='replpass',
master_log_file='${MASTER_LOG_FILE}',
master_log_pos=${MASTER_LOG_POS};
start slave;"\
| mysql -uroot -pxxxxxx
It is success to configuration with get data from slaves as follows.

Conclusion
So far, you’ve learned how to organize your slaves by leveraging the data. Before we start, we couldn’t show you all the scripts, just like you said. Of course, if only a few hundred lines, simple script but this cannot be the correct answer.
I don’t want to pull the data into the “scp”, but I can come through nc utility. Not a classic Binlog position… It’s even simpler to solve with GTID.
My solution is just one of a case not even more than that.
